亡灵之猫 - 2013/2/9 5:34:00
天朝上国的文明历史浩浩汤汤、荡气回肠,而汉字无疑是贯穿于天朝历史中的那条紧密而清晰的线索。优雅华丽的汉字以其简洁、形象且富有艺术气质的特点,深远的影响了整个东亚的历史文化,创造了人类文字领域叹为观止的成就,为壮丽的东方文化巨龙画上了闪耀的点睛之笔;不仅仅是如此,积累数千年之久的汉字文化代代相传、威名远扬,更为今天信息时代背景下的世界文明留下了一个让人无比头痛的巨大难题(被拍飞
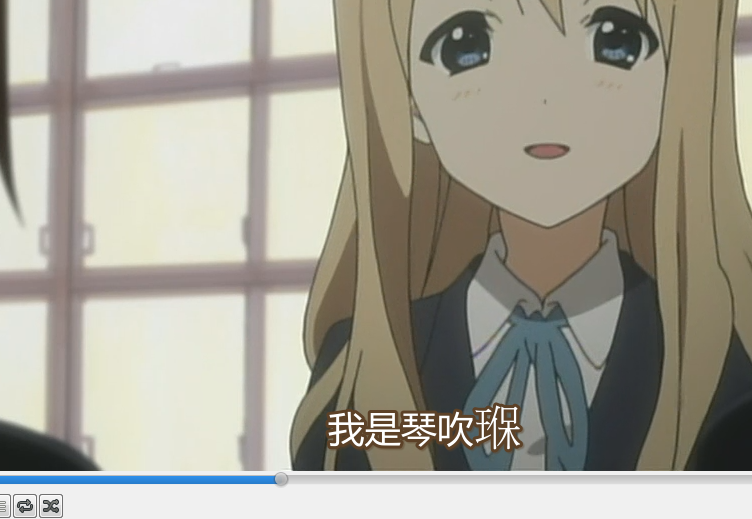
下图是咱们死宅们触手可及问题,来自华盟字幕组的字幕(大小姐中枪):
---------------------------------- 废话内容分割线 ------------------------------
与我们今天所知的西方文字体系不同,汉字并不是单纯的表音字符,而是音形同体甚至更加偏向于形的文字体系。
在表音字母盛行的西方文化中,文字几乎都是可以在有限且封闭的字母集合内就能完美陈述的,字母单元在单一次元内,通过音节顺序的拼写即可构成文字。
然而中文则大不相同,虽然汉字的构成单元极其简单,仅仅只是“横”、“竖”、“撇”、“点”、“折”这几个最基本的单元,但是我们的老祖宗们却恰恰是让简单的问题变复杂的高手、高高手。本着1生2、2生3、3生无穷信息学原理,汉字采取了让西方文字汗颜的多次元造字技术。即便在有限的笔画集合内,中文还根据形、神的需要衍生“长横”、“短横”、“横撇”、“竖撇”、“竖点”、“捺”、“横折”、“竖折”、“折钩”(呼~大口喘气)等等,超过30余种变化;而各种笔画又在一个相对有限度的二次元范围内进一步构成了简单的类似偏旁部首的字根元素,而这些元素又在网格形态上进步一部构成“左右”、“上下”、“包围”、“半包围”等结构,在此基础上一些复杂的文字还发生了结构的迭代组合;不仅如此(还有啊?),汉字构型还需要进一步结合美学原理,在“形”的基础上进一步进行“神”的优化;除此之外(有完没完啊!!),由于新生事物的产生,汉字还在不断的变化,还在不断的产生新字(例如元素周期表里那些莫名其妙的东西)。
文字中包含了如此复杂的,多次元的文化,这让咱们这些整天坐在电脑面前,脑子只能处理二次元信息的死宅们逢杀必死。
面对这样一个开放集合的汉字造字体系,让信息学的砖家们全部变成资深汉字研究的叫兽?这显然是可不行的。
于是最讨厌复杂事物的信息学砖家们决定用空间换时间,采取穷举的方式来管理汉字,让开放集合中的汉字最终在存储器的进步下,在人类大脑记忆能力的限制下,变成有限集合,这就是传说中的——汉字编码技术。
---------------------------------- 升级后的废话分割线 ------------------------------
在那遥远而混沌的年代,爸爸国的技术人员们炫耀着自己的计算机技术不可一世的时候,牙关紧咬至嘴角喷血的天朝有识青年们心中那无比伟岸的志向萌芽了~
然而那时爸爸国制的都是8个开关一组管理文字的古董机器,8个开关256种组合方式根本就不可能装得下辉煌灿烂的天朝文化历史成就,于是本着超英赶美的光荣口号,天朝人士主动出钱出物,把8个开关的设计变成了16个一组,这次就有65536种组合方式了,于是汉字编码成为了可能(大雾……)
经历了无数的磨难,丑媳妇熬成了婆,热血青年终于蜕变成了满口胡话,白发苍苍的砖家、叫兽们,年轻时代的满腔热血终于中出得子,收录了6000余汉字的GB2312-80编码标准诞生了。
GB2312编码标准如同混沌大地中亮起的圣光,引导者天朝大地携带者自己灿烂的文化,拖家带口的走向了信息化的时代;然而由于天朝人口的急速膨胀,学识的急速提升,6000个汉字的GB2312也终于落到了缺少足够的乳汁喂养中华儿女的窘境。
与此同时世界各国的有为青年如雨后春笋般的觉醒,文字编码不断的膨胀,国际标准的字符集从ISO-8859-1逐渐产生ISO-8859-2、3、4直到16。
“哦~不!!!TMD太可怕了!!!”那些妄图统治世界的大佬们终于坐不住了,技术屌丝如此这般的遍地开花,这个世界还怎么统一?!于是家长大人们拯救世界的圣婴——Unicode诞生了,圣战的火焰快速蔓延,世界快速的团结到了圣光之下。当然也有一些不太听话的大孩子,例如被西方学者视为黑暗力量的东方巨龙~
龙是传说中的生物,人们预料到了它庞大的胃口,当时却没有预料到它如此庞大的胃口 ><
把中、日、韩汉字按照相近性整合后形成的统汉字体系并不能拯救汉字的数量,在轻松吞噬了世界诸多文字后,Unicode却因为汉字而失控像气球一样的膨胀,仅仅CJK文字区就收录20902个汉字,数百倍于其他很多文字。
回头接着说天朝的有识人士,GB2312已经弹尽粮绝的时候,汉字编码走到了一个三叉路口,未来要么放弃过去革新自我,选择跟随列强走上Unicode的幸福道路,要么续写祖宗传统,利用天朝勤劳善良的劳动者的牺牲奉献,把GB2312发扬光大。
革命家们选择了前者,诞生了GB13000,编码与Unicode一致;
而这次,并不是国内有识之士,而是一只有$的西洋大鳄挑起了拯救民族文化的大旗,利用中华民族智慧的结晶GB2312的剩余价值空间,不断扩展自家的936编码集合,最终形成了更加史诗的GBK体系。
GBK的K其实就是汉语拼音Kuozhan(扩展)的缩写,它从来就没有被天朝正式承认为国家标准,当时却因为在西洋大鳄的窗户里闪耀出公关队伍七彩神光而神格化,最终成为了超越GB13000的事实标准。
GBK收录了21003个汉字,比Unicode的CJK统一汉字区还多收录了101个汉字,以至于Unicode后来不得不暂时使用一个特殊的区段(E8XX)来编码这些汉字。
GBK续写了华丽的历史,并且加速让“窗户”在中华大地上花儿遍野,其他诸多针对Unicode而生的新生代操作系统都只能通过iconv之类的对照库去被动的兼容。
然而GBK终究被天朝当初所涉及的16个开关所制约,逐渐老化并被Unicode标准上所诞生的多种优秀编码技术(如UTF-8)所超越,文字容量也随着Unicode的CJK扩展A区和扩展B区的出现而黯然失色,随着计算机存储器价格越来越低廉,此时的Unicode编码早已超出了16位二进制数的65536总数限制,收录汉字超过10万个。
天朝人民终于幡然醒悟,原来这个世界是需要爸爸的,是需要统一的,Unicode才是真正的未来。
而今面对悠远而根深的GBK体系,汉字的问题有一次复杂化了。
充满战略眼光的天朝有识之士从哲学层面分析了中文字符编码技术的发展,并最终审时度势提出了——“Unicode和GBK现在共存,并将长期处于并存状态”。
深刻事实,最终产生了GB18030-2005的折中方案。遵循中庸之道,老的就遵守GBK,新的就靠近Unicode吧。
GB18030表示文字的开关的数量再次提升一倍,至32个开关(42亿编码空间),收录汉字70217个。
---------------------------------- 废话完结的分割线 ------------------------------
好吧黑历史回顾完了(呼~
回头再来说说大小姐中枪的问题。其实猫忍受这个问题很久了,而且K-ON!已经被猫封存很久,但是紬紬这个称呼几乎已经进入某猫作为死宅的日常用语,刻入了灵魂,此时看到这个别扭的乱码,不禁强烈的违和感涌上心头,不由得考据癖复发……
说到这里也许有人坐不住了,觉得某猫似乎是站在伸手党的角度上开始指责和质疑汉化组的劳动。
其实情况恰恰完全相反,猫考据之后发现的事实真相是,出现这个乱码的根源问题并不是字幕组的大神们的错误,而是因为字幕组的大神们极其严谨的精神被黑暗的历史所枪杀所致的。
首先要说起大小姐的名字:琴吹 紬
紬是日文汉字,很少出现于现在常用中文,看到“紬”字第一眼很多人可能会认为中文中读作Xiu(袖),然而这个字其实读作Chou2,语意和“绸”字一致。
“紬”字虽然看上去没什么大不了的,但是它在现代信息的编码中却拥有可怕的黑历史,大小姐可谓连中数枪。
日文汉字、中国大陆汉字、香港、台湾地区的使用的汉字各有不同,尤其中国大陆目前使用的汉字,是在最近几十年来才进行过一轮简化的汉字,常用字与很多古字都有所不同。
黑历史第一谈>
不过你知道吗?“紬”这个几乎目前只能见于考古文献的字居然也有简化汉字(orz),跟随简化汉字所使用的部首“绞丝旁”,写作“䌷”,而华盟字幕组的字幕在制作简体版的时候也确实进行了这样的修正。
黑历史第二谈>
猫之前介绍字符编码历史的时候曾经说过,GBK发布之初,比Unicode的CJK统汉字区多收录了101个汉字,很不幸,简化字“䌷”正好就在其中之列,于是Unicode使用了特殊的E837行编码。
黑历史第三谈>
1999年Unicode发布了CJK统汉字扩充A区方案(34xx到4Dxx),“䌷”终于名正言顺进驻Unicode,编码改为4337
问题也就出现在了这段黑历史上,“䌷”字其实在Unicode中现在处于同一字对应两个编码的状态,大多数可以输入这个字的中文输入法采用了古老的标准E837,大多数的内码转换工具也是如此;而大多数现在的中文字体则支持了新的标准4337。目前的Windows字体除了历史悠久的“宋体”之外,其余的常用字体几乎都没有收录E837的“䌷”字(微软雅黑、仿宋、文泉驿正黑),因此即便计算机上能够显示这个字也必须依靠映射到宋体才能实现,Linux下的用户即便是正确的输入,“䌷”字也可能无法正确的被显示(没有宋体),这就是一切问题的根源。
那么解决的方案其实也就剩下两个:
1. 用没有争议繁体字“紬”替换,本来人家大小姐的名字就是这个字
2. 用4337的“䌷”替换E837的“”(当然,输入法就只有依靠开发者来努力了)
下图是按照方案2修改后的效果: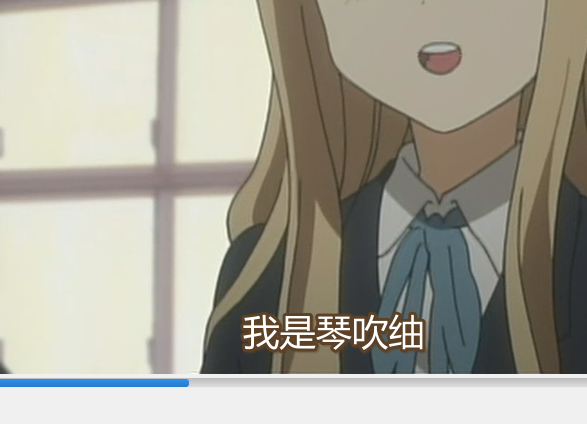
以上
文章的所有观点只代表猫的个人观点,黑历史描述有歪曲和恶搞的成分,并不针对任何组织和个人,切勿认真
转载随意
文内所有参考数据资料来自:
汉典 http://http://www.zdic.net/
维基百科 http://zh.wikipedia.org/
最后祝大家新年快乐
下图是咱们死宅们触手可及问题,来自华盟字幕组的字幕(大小姐中枪):
---------------------------------- 废话内容分割线 ------------------------------
与我们今天所知的西方文字体系不同,汉字并不是单纯的表音字符,而是音形同体甚至更加偏向于形的文字体系。
在表音字母盛行的西方文化中,文字几乎都是可以在有限且封闭的字母集合内就能完美陈述的,字母单元在单一次元内,通过音节顺序的拼写即可构成文字。
然而中文则大不相同,虽然汉字的构成单元极其简单,仅仅只是“横”、“竖”、“撇”、“点”、“折”这几个最基本的单元,但是我们的老祖宗们却恰恰是让简单的问题变复杂的高手、高高手。本着1生2、2生3、3生无穷信息学原理,汉字采取了让西方文字汗颜的多次元造字技术。即便在有限的笔画集合内,中文还根据形、神的需要衍生“长横”、“短横”、“横撇”、“竖撇”、“竖点”、“捺”、“横折”、“竖折”、“折钩”(呼~大口喘气)等等,超过30余种变化;而各种笔画又在一个相对有限度的二次元范围内进一步构成了简单的类似偏旁部首的字根元素,而这些元素又在网格形态上进步一部构成“左右”、“上下”、“包围”、“半包围”等结构,在此基础上一些复杂的文字还发生了结构的迭代组合;不仅如此(还有啊?),汉字构型还需要进一步结合美学原理,在“形”的基础上进一步进行“神”的优化;除此之外(有完没完啊!!),由于新生事物的产生,汉字还在不断的变化,还在不断的产生新字(例如元素周期表里那些莫名其妙的东西)。
文字中包含了如此复杂的,多次元的文化,这让咱们这些整天坐在电脑面前,脑子只能处理二次元信息的死宅们逢杀必死。
面对这样一个开放集合的汉字造字体系,让信息学的砖家们全部变成资深汉字研究的叫兽?这显然是可不行的。
于是最讨厌复杂事物的信息学砖家们决定用空间换时间,采取穷举的方式来管理汉字,让开放集合中的汉字最终在存储器的进步下,在人类大脑记忆能力的限制下,变成有限集合,这就是传说中的——汉字编码技术。
---------------------------------- 升级后的废话分割线 ------------------------------
在那遥远而混沌的年代,爸爸国的技术人员们炫耀着自己的计算机技术不可一世的时候,牙关紧咬至嘴角喷血的天朝有识青年们心中那无比伟岸的志向萌芽了~
然而那时爸爸国制的都是8个开关一组管理文字的古董机器,8个开关256种组合方式根本就不可能装得下辉煌灿烂的天朝文化历史成就,于是本着超英赶美的光荣口号,天朝人士主动出钱出物,把8个开关的设计变成了16个一组,这次就有65536种组合方式了,于是汉字编码成为了可能(大雾……)
经历了无数的磨难,丑媳妇熬成了婆,热血青年终于蜕变成了满口胡话,白发苍苍的砖家、叫兽们,年轻时代的满腔热血终于中出得子,收录了6000余汉字的GB2312-80编码标准诞生了。
GB2312编码标准如同混沌大地中亮起的圣光,引导者天朝大地携带者自己灿烂的文化,拖家带口的走向了信息化的时代;然而由于天朝人口的急速膨胀,学识的急速提升,6000个汉字的GB2312也终于落到了缺少足够的乳汁喂养中华儿女的窘境。
与此同时世界各国的有为青年如雨后春笋般的觉醒,文字编码不断的膨胀,国际标准的字符集从ISO-8859-1逐渐产生ISO-8859-2、3、4直到16。
“哦~不!!!TMD太可怕了!!!”那些妄图统治世界的大佬们终于坐不住了,技术屌丝如此这般的遍地开花,这个世界还怎么统一?!于是家长大人们拯救世界的圣婴——Unicode诞生了,圣战的火焰快速蔓延,世界快速的团结到了圣光之下。当然也有一些不太听话的大孩子,例如被西方学者视为黑暗力量的东方巨龙~
龙是传说中的生物,人们预料到了它庞大的胃口,当时却没有预料到它如此庞大的胃口 ><
把中、日、韩汉字按照相近性整合后形成的统汉字体系并不能拯救汉字的数量,在轻松吞噬了世界诸多文字后,Unicode却因为汉字而失控像气球一样的膨胀,仅仅CJK文字区就收录20902个汉字,数百倍于其他很多文字。
回头接着说天朝的有识人士,GB2312已经弹尽粮绝的时候,汉字编码走到了一个三叉路口,未来要么放弃过去革新自我,选择跟随列强走上Unicode的幸福道路,要么续写祖宗传统,利用天朝勤劳善良的劳动者的牺牲奉献,把GB2312发扬光大。
革命家们选择了前者,诞生了GB13000,编码与Unicode一致;
而这次,并不是国内有识之士,而是一只有$的西洋大鳄挑起了拯救民族文化的大旗,利用中华民族智慧的结晶GB2312的剩余价值空间,不断扩展自家的936编码集合,最终形成了更加史诗的GBK体系。
GBK的K其实就是汉语拼音Kuozhan(扩展)的缩写,它从来就没有被天朝正式承认为国家标准,当时却因为在西洋大鳄的窗户里闪耀出公关队伍七彩神光而神格化,最终成为了超越GB13000的事实标准。
GBK收录了21003个汉字,比Unicode的CJK统一汉字区还多收录了101个汉字,以至于Unicode后来不得不暂时使用一个特殊的区段(E8XX)来编码这些汉字。
GBK续写了华丽的历史,并且加速让“窗户”在中华大地上花儿遍野,其他诸多针对Unicode而生的新生代操作系统都只能通过iconv之类的对照库去被动的兼容。
然而GBK终究被天朝当初所涉及的16个开关所制约,逐渐老化并被Unicode标准上所诞生的多种优秀编码技术(如UTF-8)所超越,文字容量也随着Unicode的CJK扩展A区和扩展B区的出现而黯然失色,随着计算机存储器价格越来越低廉,此时的Unicode编码早已超出了16位二进制数的65536总数限制,收录汉字超过10万个。
天朝人民终于幡然醒悟,原来这个世界是需要爸爸的,是需要统一的,Unicode才是真正的未来。
而今面对悠远而根深的GBK体系,汉字的问题有一次复杂化了。
充满战略眼光的天朝有识之士从哲学层面分析了中文字符编码技术的发展,并最终审时度势提出了——“Unicode和GBK现在共存,并将长期处于并存状态”。
深刻事实,最终产生了GB18030-2005的折中方案。遵循中庸之道,老的就遵守GBK,新的就靠近Unicode吧。
GB18030表示文字的开关的数量再次提升一倍,至32个开关(42亿编码空间),收录汉字70217个。
---------------------------------- 废话完结的分割线 ------------------------------
好吧黑历史回顾完了(呼~
回头再来说说大小姐中枪的问题。其实猫忍受这个问题很久了,而且K-ON!已经被猫封存很久,但是紬紬这个称呼几乎已经进入某猫作为死宅的日常用语,刻入了灵魂,此时看到这个别扭的乱码,不禁强烈的违和感涌上心头,不由得考据癖复发……
说到这里也许有人坐不住了,觉得某猫似乎是站在伸手党的角度上开始指责和质疑汉化组的劳动。
其实情况恰恰完全相反,猫考据之后发现的事实真相是,出现这个乱码的根源问题并不是字幕组的大神们的错误,而是因为字幕组的大神们极其严谨的精神被黑暗的历史所枪杀所致的。
首先要说起大小姐的名字:琴吹 紬
紬是日文汉字,很少出现于现在常用中文,看到“紬”字第一眼很多人可能会认为中文中读作Xiu(袖),然而这个字其实读作Chou2,语意和“绸”字一致。
“紬”字虽然看上去没什么大不了的,但是它在现代信息的编码中却拥有可怕的黑历史,大小姐可谓连中数枪。
日文汉字、中国大陆汉字、香港、台湾地区的使用的汉字各有不同,尤其中国大陆目前使用的汉字,是在最近几十年来才进行过一轮简化的汉字,常用字与很多古字都有所不同。
黑历史第一谈>
不过你知道吗?“紬”这个几乎目前只能见于考古文献的字居然也有简化汉字(orz),跟随简化汉字所使用的部首“绞丝旁”,写作“䌷”,而华盟字幕组的字幕在制作简体版的时候也确实进行了这样的修正。
黑历史第二谈>
猫之前介绍字符编码历史的时候曾经说过,GBK发布之初,比Unicode的CJK统汉字区多收录了101个汉字,很不幸,简化字“䌷”正好就在其中之列,于是Unicode使用了特殊的E837行编码。
黑历史第三谈>
1999年Unicode发布了CJK统汉字扩充A区方案(34xx到4Dxx),“䌷”终于名正言顺进驻Unicode,编码改为4337
问题也就出现在了这段黑历史上,“䌷”字其实在Unicode中现在处于同一字对应两个编码的状态,大多数可以输入这个字的中文输入法采用了古老的标准E837,大多数的内码转换工具也是如此;而大多数现在的中文字体则支持了新的标准4337。目前的Windows字体除了历史悠久的“宋体”之外,其余的常用字体几乎都没有收录E837的“䌷”字(微软雅黑、仿宋、文泉驿正黑),因此即便计算机上能够显示这个字也必须依靠映射到宋体才能实现,Linux下的用户即便是正确的输入,“䌷”字也可能无法正确的被显示(没有宋体),这就是一切问题的根源。
那么解决的方案其实也就剩下两个:
1. 用没有争议繁体字“紬”替换,本来人家大小姐的名字就是这个字
2. 用4337的“䌷”替换E837的“”(当然,输入法就只有依靠开发者来努力了)
下图是按照方案2修改后的效果:
以上
文章的所有观点只代表猫的个人观点,黑历史描述有歪曲和恶搞的成分,并不针对任何组织和个人,切勿认真
转载随意
文内所有参考数据资料来自:
汉典 http://http://www.zdic.net/
维基百科 http://zh.wikipedia.org/
最后祝大家新年快乐
